
Integrates with existing projects
Built with the broader community
Dask is open source and freely available. It is developed in coordination with other community projects like NumPy, pandas, and scikit-learn.
NumPy

Dask arrays scale NumPy workflows, enabling multi-dimensional data analysis in earth science, satellite imagery, genomics, biomedical applications, and machine learning algorithms.
pandas

Dask dataframes scale pandas workflows, enabling applications in time series, business intelligence, and general data munging on big data.
scikit-learn
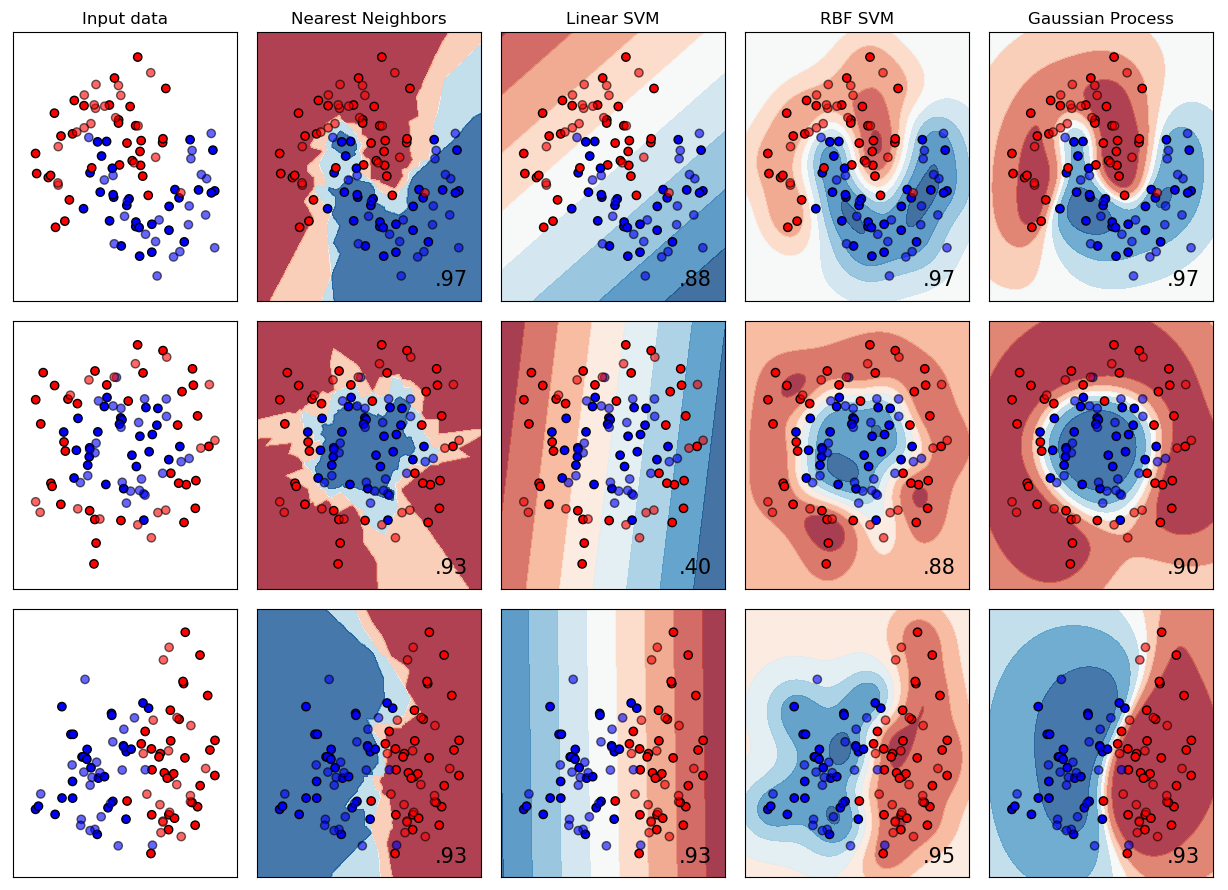
Dask-ML scales machine learning APIs like scikit-learn and XGBoost to enable scalable training and prediction on large models and large datasets.
Familiar for Python users
and easy to get started
Dask uses existing Python APIs and data structures to make it easy to switch between NumPy, pandas, scikit-learn to their Dask-powered equivalents.
You don't have to completely rewrite your code or retrain to scale up.
Learn About Dask APIs »# Arrays implement the NumPy API
import dask.array as da
x = da.random.random(size=(10000, 10000),
chunks=(1000, 1000))
x + x.T - x.mean(axis=0)# Dataframes implement the pandas API
import dask.dataframe as dd
df = dd.read_csv('s3://.../2018-*-*.csv')
df.groupby(df.account_id).balance.sum()# Dask-ML implements the scikit-learn API
from dask_ml.linear_model \
import LogisticRegression
lr = LogisticRegression()
lr.fit(train, test)Scale up to clusters
or just use it on your laptop
Dask's schedulers scale to thousand-node clusters and its algorithms have been tested on some of the largest supercomputers in the world.
But you don't need a massive cluster to get started. Dask ships with schedulers designed for use on personal machines. Many people use Dask today to scale computations on their laptop, using multiple cores for computation and their disk for excess storage.
Learn About Dask Schedulers »
Customizable
Enabling you to parallelize internal systems
Not all computations fit into a big dataframe.
Dask exposes lower-level APIs letting you build custom systems for in-house applications. This helps open source leaders parallelize their own packages and helps business leaders scale custom business logic.

Powered by Dask
These software projects are well-integrated with Dask, or use Dask to power components of their infrastructure.

pandas
Tabular data analysis

NumPy
Array and numerical computing
scikit-learn
Machine learning in Python
Scikit-image
A collection of algorithms for image processing in Python
XGBoost
Gradient boosted trees for machine learning
XGBoost can use Dask to bootstrap itself for distributed training
RAPIDS
GPU Accelerated libraries for data science
XArray
Brings the labeled data power of pandas to the physical sciences, by providing N-dimensional variants of the core pandas data structures
Iris
A Python library for analysing and visualising Earth science data

Pangeo
A community effort for big data geoscience in the cloud
Prefect
A workflow management system, designed for modern infrastructure

Napari
Multi-dimensional image viewer for Python

Snorkel
Programmatically build training data for machine learning
Datashader
Visualization packages for large data
Intake
A lightweight package for finding, investigating, loading and disseminating data
TPOT
A Python Automated Machine Learning tool that optimizes machine learning pipelines using genetic programming
MDAnalysis
A Python toolkit to analyze molecular dynamics trajectories generated by a wide range of popular simulation packages
Stumpy
A Python library that can be used for a variety of time series data mining tasks
Featuretools
A Python framework for automated feature engineering
Cesium-ML
Open-Source machine learning for time series analysis
SkyPortal
An astronomical data platform
Conda Forge
Community effort to build and maintain Conda packages

DataPrep
Data preparation in Python
LightGBM
Gradient boosted trees for machine learning
LightGBM can use Dask to bootstrap itself for distributed training
Xarray-Spatial
Geospatial raster analysis in Python; extensible with Numba, scalable with Dask
Karthotek
Manage tabular data in a blob store
SatPy
Library for reading and manipulating meteorological remote sensing data and writing it to various image and data file formats
Streamz
A package to help build pipelines to manage continuous streams of data
Scikit-allel
Provides utilities for exploratory analysis of large scale genetic variation data
tsfresh
Automatic extraction of relevant features from time series
